Concurrency and distributed systems
- Logic clocks
- Logic clock: number counters
- Lamport and vector clocks represents partial orders (not total order, have no idea about the orders among some events) of events in distributed systems.
- Lamport clock: one counter at each node. If two events (e.g., A sending and B receiving) have a causality (i.e., happens-before relation), thus clock(A) < clock(B). However, given clock(A) < clock(B), we cannot say A happens before B, as the clock increases even if there is no synchronization among nodes.
- Vector clock is design for that weakness of lamport clock. N counters at each node, and each of counters represent the last syncrhonized state of one node. It can conclude that A happens before B if clock(A) < clock(B), which means every counter of A is smaller than B’s.
- Concurrency issues and synchronization primitives
- Memory barrier
- Data race and race condition
- Data race: two concurrent memory access and one of them is a write.
- Race condition: application-level atomicity
- Fault -> error -> failure
- Fault: the root cause of the errors and failures.
- Error: if the system doesn’t correctly handle a fault, it would turn out as an error.
- Failure: at the overall level, you get the unexpected result from a system.
- For example, there is a network partition fault in a DFS. However, the system doesn’t have enough machanism to process it (error), and finally leading to a split-brain problem. Thus the users would retrieve inconsistent (unexpected) data from the DFS (failure).
- Failure model: When a system fails, how does that failure appear at the interface of a component?
- Fail-stop: module crash failure.
- Fail-fast: frequently detect system states and immediately deal with situations that might lead to failures once detecting them.
- Fail-safe: the component is safe in the face of failure, but might get performance degradation, e.g., fail-slow failure, meta-stable failure, scalability failure.
- Fail-soft: leads to functionality degradation.
- [Consistency model]
- Consistency model can only define the non-overlapped read/write events.
- Strong consistency = linerizability: every read can retrieve the latest write. In other words, there is exactly one order between events. The write orders are the read orders. And there order are consistency with their real-time order.
- Sequential consistency: as long as the reads from multiple nodes/processes are in the same order, even if they are opsite with the write orders.
- Serializability is used in database. It is the gold standard in isolation, the I in ACID. A system that guarantees serializability is able to process transactions concurrently, but guarantees that the final result is equivalent to what would have happened if each transaction was processed individually, one after other (as if there were no concurrency).[^1][^2]
[^1] http://www.bailis.org/blog/linearizability-versus-serializability/
[^2] https://fauna.com/blog/serializability-vs-strict-serializability-the-dirty-secret-of-database-isolation-levels
- Difference between concurrency and parallism
- Parallism: Multiple tasks that are synchronous inside and run the same computing logic. It is used in CPU-bound applications, like complex math processing. (A program is CPU bound if it would go faster if the CPU were faster)
- Concurrency: Multiple different tasks run asynchronously and synchronize sometimes. It is used for IO-bound applications. (A program is I/O bound if it would go faster if the I/O subsystem was faster.)
Formal methods
- Lectures of model checking
- Dynamic Partial-Order Reduction for Model Checking Software
- Partial-Order Methods for the Veri cation of Concurrent Systems
Model checking is an approach to exploring states in an model abstracted from implementations for checking the conformance to the specification/properties. Here the model can be in different froms, such as, finite state machine with S: states, T: transitions.
Due to the need of exploring all states, it faces state explosion. Especially in the concurrent systems, the partial orders between concurrent transitions make the search space larger. To solve this problem, previous works proposed statically and dynamically partial order reduction, which skips exploring different order os transitions which are independent.
Statically: persistent set, sleep set (TODO)
Dynamically:
- Model checking
- Model a system with specific methods
- Hardware -> finite state machine
- Concurrency applications -> transition systems
- Distributed systems -> asynchronous message passing model or distributed shared memory (DSM)
- Traverse the search space represented by the model
- Space explosion -> state pruning algorithoms
- Checking if states satisfy requirements.
- Difference with symbolic executions:
- Model a system with specific methods
- Rosette: Synthesis and Verification for All
Programming languages
- Declarative language
- E.g., SQL, HTML and CSS.
- Functional programming: TODO
- Imperative languages
- C, C++, Java, Javascript, BASIC, Python, Ruby, and most other programming languages are imperative. As a rule, if it has explicit loops (for, while, repeat) that change variables with explicit assignment operations at each loop, then it’s imperative.
- ref
File systems / Storage
I/O stack
Question: when issuing a file operation, how could it know if the data is already in page cache? Is it searching buffer headers?
BIO layer
The mapping between page cache and block devices are blocks. The size of blocks varies between the size of sectors (512B) and the size of pages (4KB). To build the such a mapping, buffer head is proposed, which records the information of each block, including which device and block it persists to and which page it is cached.
BIO -> IO scheduler -> combined request -> request queue (sequentially queued requests)
When flushing page cache to block devices or reading block devices to page cache, a BIO struct is generated, which builds the connection between a set of non-continous pages and a set of continous sectors in the block devices.
struct bio {
...
struct bvec_iter bi_iter;
unsigned short bi_vcnt;
struct bio_vec *bi_io_vec;
...
}
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
struct bvec_iter {
sector_t bi_sector; /* device address in 512 byte sectors */
unsigned int bi_size; /* residual I/O count */
unsigned int bi_idx; /* current index into bvl_vec */
unsigned int bi_bvec_done; /* number of bytes completed in current bvec */
}
Storage organization types
- Block storage : Store data in fixed-length blocks without any other informations.
- Object storage : Metadata and data of objects are organized in a flat view. It's more suitable for scenarios that there are no hierarchy relationship among data.
- File storage : Files, as units, are organized in a hierarchy.
Storage device types
| Hierarchy | Storage Technique | Bus | Interface to CPUs | Speed |
| ----------------- | ---------------------------------- | ----- | -------------------- | ----- |
| Register | - | | - | |
| Cache | SRAM | | - | |
| Main Memory | DRAM | DIMM | DDR3/4/5 | |
| Persistent Memory | Optane (aka 3D-Xpoint), Flash NAND | DIMM* | DDR3/4/5 | |
| Flash Disk | Flash NAND | PCIe* | NVMe (based on PCIe) | |
| Traditional Disk | Magnetic disk | AHCI* | SATA | |
- See [CPU arch](#Architecture/hardware) to know the buses.
- *Dual In-Line Memory Module (DIMM)
- *Peripheral Component Interconnect Express (PCIe)
- *Advanced Host Controller Interface (AHCI)
- Reference
- [Modern Storage Hierarchy: From NAND SSD to *3D XPoint* (*Optane*) PM](https://www.josehu.com/technical/2021/01/01/ssd-to-optane.html)
Raid, device mapper
http://www.ssdfans.com/?p=8210 https://blog.csdn.net/fengxiaocheng/article/details/103258791 https://www.cnblogs.com/zhangsanlisi411/articles/16751546.html
Linux kernel / OS kernel
Macro/Micro/Exo kernels
-
kernel extension: flexibility (customization)
- rCore-Tutorial-Book: unix-like OS written in Rust
- Eliminating Receive Livelock in an Interrupt-driven Kernel
Virtualization
- Writing a hypervisor from sctratch
- Book: Hardware and Software Support for Virtualization
-
Core slicing: closing the gap between leaky confidential VMs and bare-metal cloud
- Constant and invariant CPU
- Variant TSC: The first generation of TSC, the TSC increments could be impacted by CPU frequency changes.
- Constant TSC: The TSC increments at a constant rate, even CPU frequency get changed. But the TSC could be stopped when CPU run into deep C-state.
- Invariant TSC: The invariant TSC will run at a constant rate in all ACPI P-, C-, and T-states.
How is rdtsc implemented in KVM guest?
- Constant TSC: ensures that the duration of each clock tick is uniform and supports the use of the TSC as a wall clock timer even if the processor core changes frequency. however it does change on C state.
- Invariant TSC: runs at a constant rate in all ACPI P-, C-. and T- states.
- Non-stop TSC: has the properties of both Constant and Invariant TSC.
- Why the KVM TSC offset keeps changing?
- The constant TSC frequency might change in C state, so KVM need to adjust it accordingly with the geust TSC frequency.
- Advanced Configuration and Power Interface (ACPI) TODO???
Kernel bypass
- Junction
- DPDK
Architecture/hardware
- Before 2012, CPU + two chips design (north-bridge Memory-control Hub (MCH) and south bridge I/O Control Hub (ICH))
- After, MCH is integrated into the CPU
- A classic figure of general CPU arch
Basic concepts
- RISC/CISC, SoC, bus, north birdge, sourth bridge or I/O Controller Hub (ICH) or a Platform Controller Hub (PCH)
- Root complex: Connect between CPU, memory, and PCIe devices
- Root complex includes DMA module
- The root complex generates transaction requests on behalf of the CPU. In response to CPU commands, it generates configuraion, memory and IO requests as well as locked transaction requests on the PCI Express fabric.
- Modern CPUs don’t have a system bus (except hidden within the CPU itself). They have memory channels, PCIe root ports, and a DMI port that connects to the chipset (also called the peripheral controller hub, or PCH). The PCH contains additional devices and may have additional root ports. The root complex comprises circuitry integrated into both the CPU and PCH. (Some CPU SoCs don’t have DMI or a PCH, and all the root complex circuitry is within the CPU SoC.)
- https://www.mindshare.com/files/resources/MindShare_Intro_to_PCIe.pdf
- http://www.bi2.com.cn/biancheng/64.html
- https://blog.csdn.net/qq_37344125/article/details/136903500
- [1]. https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/ia-introduction-basics-paper.pdf
IO devices and PCIe
- PCIe
IOMMU and DMA
Data transfer between memory and hardware subsystems execept for CPU takes much CPU cycles, such as data transfer between peripheral devices and memory. Although this problem can be solved with more CPU cores, there should be more efficient solutions, i.e., Direct memory access (DMA). DMA directly transfer data between hardware subsystems and memory without the interference of CPUs. In this case, CPUs are saved for other complex computations while the customized, less complex and thus fast hardware—DMA—takes care of (can be regarded as “accelerators”) transfering data.
// TODO Bus, DMA controller, DMA engine. ref: An overview of direct memory access
// TODO cache coherence of DMA: https://www.quora.com/Can-a-DMA-engine-read-from-the-cache-What-are-the-pros-and-cons-of-this-approach
The impact of DMA On CPU—The memory bus contention between DMA and CPU: There is less memory bus contention between DMA and CPU because:
- Instructions are prefetched and not every instruction accesses memory, such as arithmetics on registers. ref
- CPU caches can minimize the number of memory accesses.
IOMMU: https://www.kernel.org/doc/Documentation/DMA-API-HOWTO.txt For virtualization and limit the memory access of devices
https://www.spiceworks.com/tech/hardware/articles/direct-memory-access/
https://www.intel.com/content/www/us/en/developer/articles/technical/memory-in-dpdk-part-2-deep-dive-into-iova.html
Pipeline and hyper-threads
- Pipeline
- Out-of-order execution
- Speculative execution
- Cycles
Memory (consistency) model
- The memory consistency model of a shared memory processor specifies how the memory system will appear to the programmer[1]. In other words, it specifies how the loads/stores on exclusive/shared memory behavior.
- The most intuitive memory model is sequential consistency, that is, every memory operations are executed in some sequential orders, seed detailed definition below. However, that is not performant, thus, several techniques are proposed to relax the memory model to improve the performance.
- Where and how are memory models (load/store behaviors) affected?
- Reorder program orders (for both uniprocessors and multiprocessors)
- Compiler: reordering of independent operations (operations on different memory objects) from a single thread view.
- CPU: such as, pipeline, which is not completely reorder, but they are overlapped.
- Cache (hardware level, only for multiprocessors)
- Load/store buffer
- CPU cache (L1, L2, LLC)
- Invalid queue
- Others
- Load a memory into a register and no re-load happens for following loads.
- Reorder program orders (for both uniprocessors and multiprocessors)
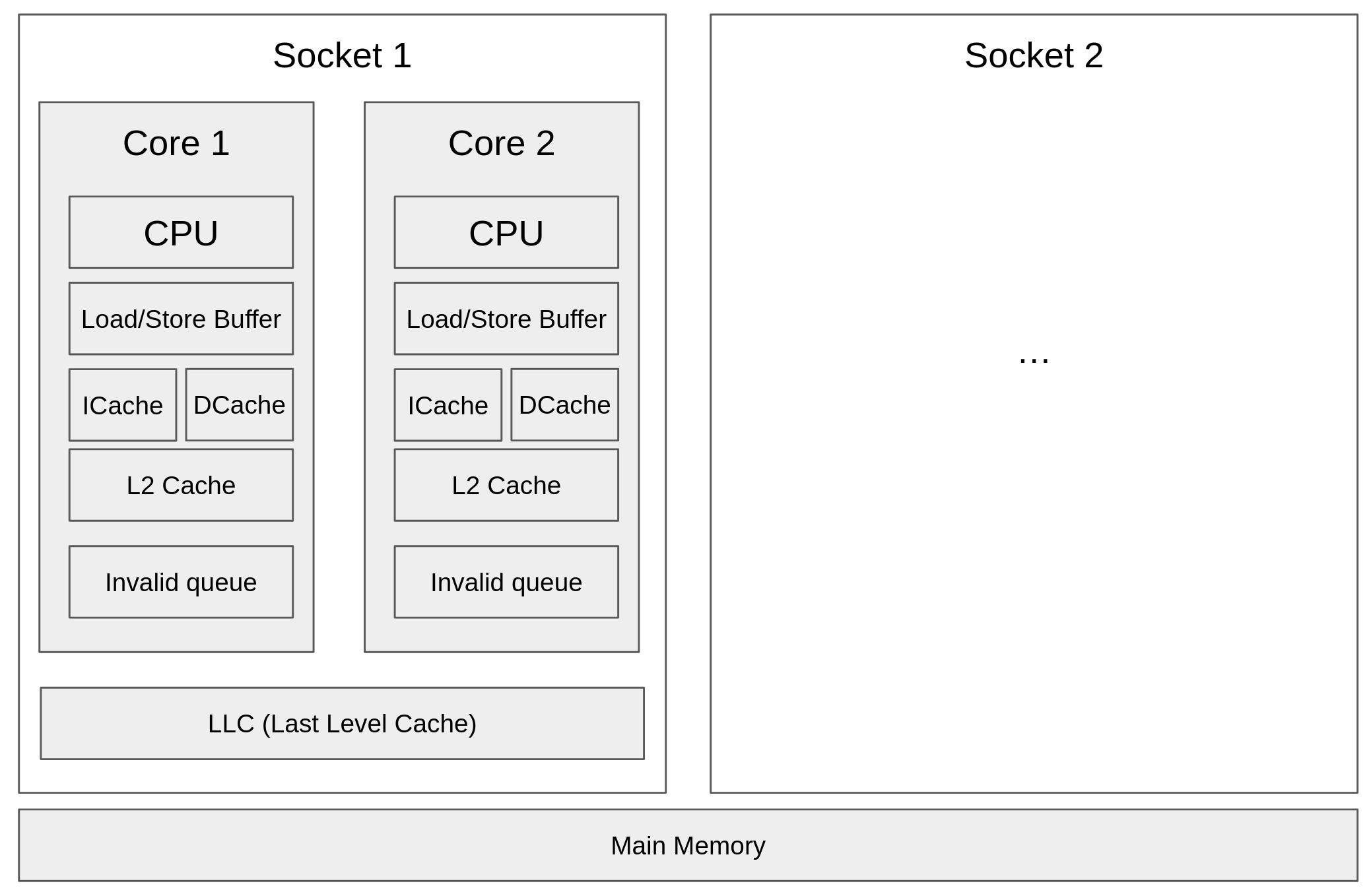
- Types of memory models
- Most strict and intuitive memory model: sequential consistency
- Memory operations of all processors are executed in some sequential orders (execute one after another) and memory operations of individual processor appear in that sequence in the order specified by its program (i.e., program order).
- Relaxed memory (consistency) model
- Relaxation comes from two points
- Relax program order among memory operations on different memory objects in individual processors.
- Relax write atomicity, that is, if a read can return before the writes are visible to all processors.
- Case study: total-store-order (TSO) [2]
- Reorder between a write and its followed read.
- A read can only return on its own cached write but on others.
- Relaxation comes from two points
- Most strict and intuitive memory model: sequential consistency
- Memory barriers
- Instructions
- C library
- barrier, fence (https://stackoverflow.com/questions/50323347/how-many-memory-barriers-instructions-does-an-x86-cpu-have)
- Bug detection on memory orders
- References
- [1] shared memory consistency models: A Tutorial
- [2] x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors
- [3] A Tutorial Introduction to the ARM and POWER Relaxed Memory Models
- [4] A Formal Model of Linux-Kernel Memory Ordering
- [5] A Primer on Memory Consistency and Cache Coherence
Cache Indentification
- TLB, Data/instruction cache
- VIPT:
- …
Cache coherence
- MSI: Modified (writable), Share (readable), Invalid
- MESI: Execlusive. The difference with the M state is that the cache block is writable (and readable) but not yet written. Once the cache line is modified, it enters M state. What’s the benefit of having E state? No write back if the cache line is exclusively owned by some but not get modified. what’s SharedLine?
-
MOSI: ??
-
Snooping:
-
Directory:
- Relation among different level of caches: inclusive, non-inclusive, exclusive
Keyword Volatile
Volatile is used to tell compiler that do not do any optimization on this variable. The optimizations can be any, for example:
- Removing Dead Stores
int x = 0;
x = 5; // This write may be optimized out
- Caching in Registers.
int flag = 0;
void updateFlag() {
flag = 1; // The compiler may keep this in a register
}
void checkFlag() {
while (flag == 0) { // flag might be optimized out as always 0
// Loop forever because the write to flag may not be visible here
}
}
- Write Coalescing and Reordering.
int status = 0;
void setStatus() {
status = 1;
status = 2; // The compiler may combine these two writes into just status = 2
}
- Loop Invariant Code Motion.
int dataReady = 0;
void pollStatus() {
for (int i = 0; i < 1000; i++) {
dataReady = 1; // The compiler might move this out of the loop or eliminate it
}
}
Performance
- Latency:
- Throughout:
-
Bandwidth:
- Cache: https://brooker.co.za/blog/2023/12/15/sieve.html
Database
ACID of transactions
- Atomicity: Either none or all of operations in one transaction is done.
- Consistency: The finally achieved state after executing all operations in a transaction should be valid. If only ensuring atomicity, it is possible that the finally achieved state is invalid even none or all is guaranteed. Because transaction logic (i.e., code) itself might be wrong, which leads to invalid states. The
consistencyis defined by concrete application logic. - Isolation: No intermidiate states are visible. Atomicity and consistency does not guarantee that intermediate states are invisible.
- Durablility: States are peristed.
Transactional memory
Transactional memory only gurantees atomicity, isolation, and partial consistency. Partial consistency means that it only ensures the memory level consistency instead of application-level logic consistency (like the credit cannot be minus).
Ways to ensure transactions
- Undo-logging: Copy the old data to the log, write the new data to the dst memory, and then commit. Once faults happens in the middle, it can undo the modification to the dst memory by copying the old data in the log, that is undo.
- Redo-logging: Copy the new data to the log and then the dst memory, finally commit. Once faults happen, just copy the new data from the log to the dst memory, that is redo.
- Copy-on-Write (CoW): Write the old data to a new memory, and then apply the modifications and finally commit, that is pointing to the new memory.
Data structure and algorithom
Big O notation and time complexity
Data structures
Red-black tree
Merkle tree
…
Performance numbers
- 1 KB of RAM or cache = 1,024 bytes
- 1 KB of disk space = 1,000 bytes
- 1 Kbps of bandwidth = 1,000 bits/second
- 1 GHz (CPU) = 1,000 MHz
- 1 CPU cycle (N Ghz -> cycle time = 1/N), generally 2-5Ghz and thus 0.2-0.5 ns per cycle.
- Register-register ADD/OR/etc. < 1 CPU cycle
- Register write ~1 cycle
- Correctly / incorrectly predicted “if” branch = 1 cycle / 10-20 cycles
- L1 (NKB each for L1i and L1d, can be different) / L2 (KB or even MB) / L3 (8-64MB) / main RAM read = 3-4 cycles / 10-12 cycles / 50-70 cycles / 100-150 cycles
- TLB hit = 0.5 - 1 cycle
- CAS = 15-30 cycles
- C function direct / indirect call = 10-20 cycles / 20-50 cycles
- Kernel syscall = 1,000 - 1,500 cycles
- Thread context switch (direct costs) = 2,000 cycles
- On NUMA, different-socket mem hierarchy access is 3 - 10x that of non-NUMA
System numbers
- Cache line size: 32 or 64 bytes